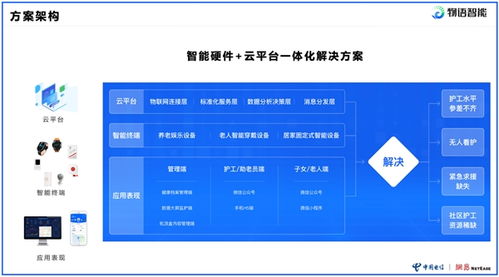
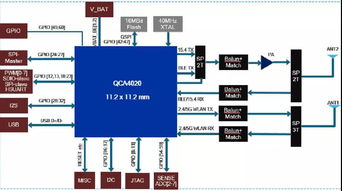
面向繼電器與直流電機控制的智能LIN從控制器MLX81150及其在物聯網服務中的創新應用
隨著物聯網技術的飛速發展,智能控制設備在工業自動化、智能家居和汽車電子等領域的需求日益增長。MLX81150作為一款專為繼電器和直流電機控制設計的智能LIN從控制器,憑借其高性能和集成化優勢,為物聯網服務提供了高效可靠的解決方案。
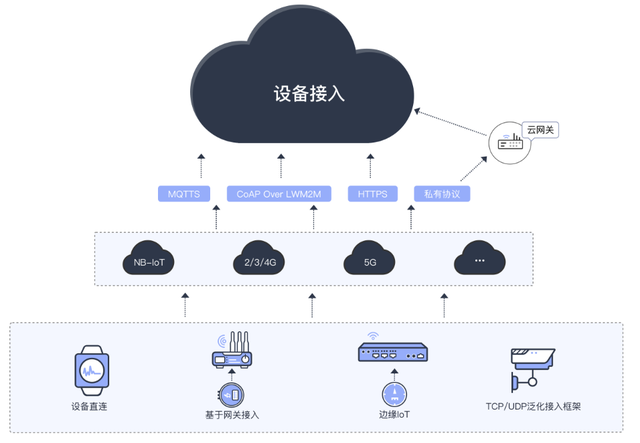
MLX81150集成了LIN通信接口、電源管理單元和多路驅動輸出,能夠直接驅動繼電器和直流電機,顯著簡化了系統設計。其內置的智能控制算法支持PWM調節和過載保護,確保電機運行的平穩性與安全性。在繼電器控制方面,MLX81150通過精確的時序管理,實現了快速響應和低功耗操作,適用于智能照明、安防系統等場景。
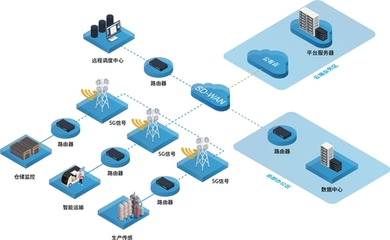
在物聯網服務中,MLX81150作為從節點,可通過LIN總線與主控制器無縫通信,實現遠程監控和數據分析。例如,在智能家居系統中,MLX81150可控制窗簾電機和家電繼電器,用戶通過手機APP即可調節設備狀態;在工業物聯網中,它能夠協同多個傳感器執行電機啟停任務,提升自動化水平。MLX81150的低成本和小尺寸特性,使其成為大規模部署的理想選擇,推動了物聯網設備的普及。
MLX81150將與5G、AI技術進一步融合,增強邊緣計算能力,為智能城市和工業4.0注入新動力。其可靠性和靈活性將持續賦能物聯網生態,實現更智能、高效的控制服務。
如若轉載,請注明出處:http://www.szguangzhuo.cn/product/47.html
更新時間:2026-06-19 03:29:09