物聯網技術應用與智慧城市服務

物聯網技術作為一種將物理世界與數字世界深度融合的前沿科技,正日益成為推動智慧城市建設與服務創新的核心驅動力。在智慧城市的框架下,物聯網技術通過傳感器、網絡通信和大數據分析,實現了對城市基礎設施、公共服務和居民生活的智能化管理,從而為城市運營效率與居民生活質量帶來顯著提升。
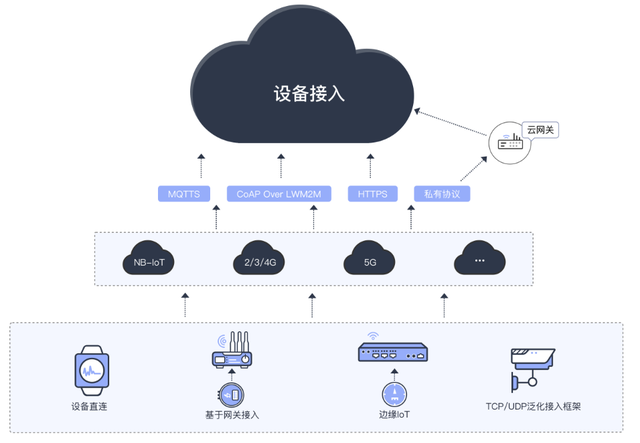
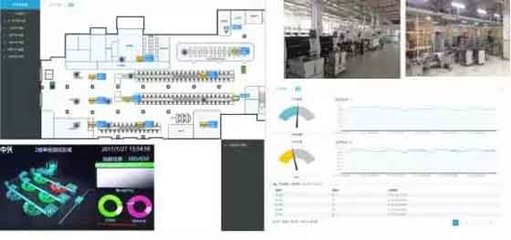
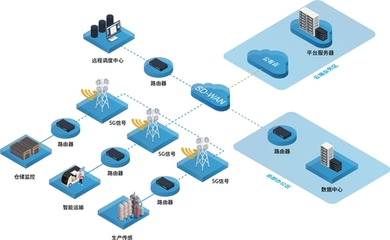
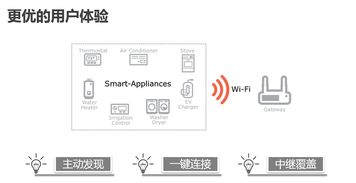
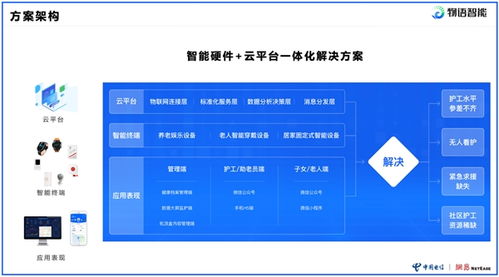
物聯網技術在智慧城市中的應用廣泛而深入。例如,在交通管理領域,通過部署智能交通信號燈和車輛傳感器,系統能夠實時監控交通流量,優化信號配時,緩解擁堵問題。在環境監測方面,物聯網設備可收集空氣質量、噪聲水平及溫濕度數據,幫助城市管理者及時制定環保措施。智能電網、智慧安防和智能家居等應用也依賴于物聯網技術,實現能源高效分配、公共安全預警以及居民生活便利化。
這些應用不僅提升了城市服務的智能化水平,還催生了多樣化的物聯網服務。物聯網服務包括平臺即服務(PaaS)和軟件即服務(SaaS),例如,云平臺可集成各類傳感器數據,提供實時監控和預測分析功能,支持城市決策。企業可利用這些服務開發定制化解決方案,如智能停車系統,用戶通過手機應用即可查找空閑車位并支付費用。物聯網服務還涵蓋設備管理、數據安全和維護支持,確保系統的可靠運行。
物聯網技術在智慧城市服務中也面臨挑戰,如數據隱私保護、系統互操作性和高成本問題。隨著5G、人工智能等技術的融合,物聯網服務將進一步擴展,推動智慧城市向更智能、可持續的方向發展。物聯網技術的應用與服務正重塑城市生態,為人類社會帶來更高效、便捷的智慧生活體驗。
如若轉載,請注明出處:http://www.szguangzhuo.cn/product/46.html
更新時間:2026-06-19 04:21:47